Azhagi Facebook Group
Azhagi Facebook Group

How to convert a PDF/Image in Tamil (Hindi, etc.) to editable Tamil (Hindi, etc.) text?
(In other words, how to effect OCR [optical character recognition] on a PDF/Image?)
Related links: convert-images-to-texts-in-many-indian-world-languages-tamil-sanskrit-etc-perfectly.php, Amazing 'Google Translate' app, Google Lens, Facebook post - 1, Facebook post - 2
Following is the PDF file, 'Samiksha-1.pdf', received from an user more than 2 weeks ago (in Sep 2019). Apart from English, it contains Tamil and Sanskrit characters too. The request from user was to help him convert the text in the PDF file to a suitable form such that he can extract that text and paste it in MS Word and read/edit the Tamil and Sanskrit text. If you observe carefully, the text is selectable from the PDF file but if you copy/paste the text in MS Word, Notepad, etc., the Tamil or Sanskrit words in the PDF file will not be decipherable. Hence, the request from the user. This kind of query comes up again and again from users, since they are not aware of what to do and how to do it. So, the objective is to convert this PDF file to such a format so that the Tamil/Sanskrit words are readable clearly and also editable. The steps for the same are listed below, if you scroll down further.
Step 1: Download and install the supremely useful 'PDFill PDF Tools' (100% FREE) from http://www.pdfill.com/pdf_tools_free.html. Note: You can use any other application to which you are accustomed to, too. I prefer 'PDFill tools'. That's all to it.
Step 2: After successful installation, start the 'PDFill PDF Tools' application and click on 'Convert PDF to Images'. Open 'Samiksha-1.pdf'.
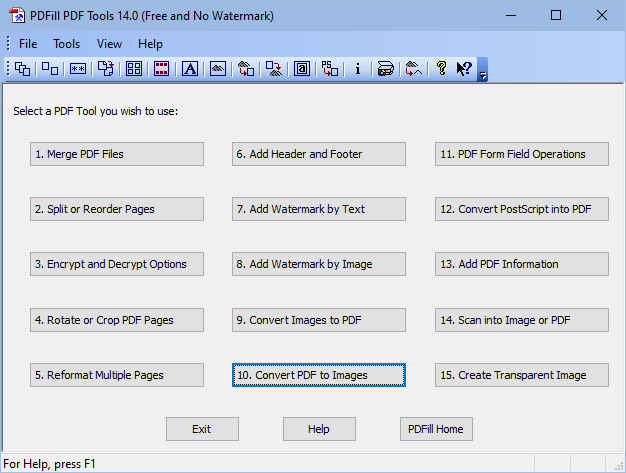
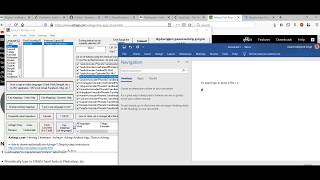
Step 3: Then, make note of the highlighted areas in the screenshot below and keep/select your settings accordingly (i.e. 300 DPI and TIF image format). The image format can be JPG also but I prefer TIF format (Single File with Multiple Pages).
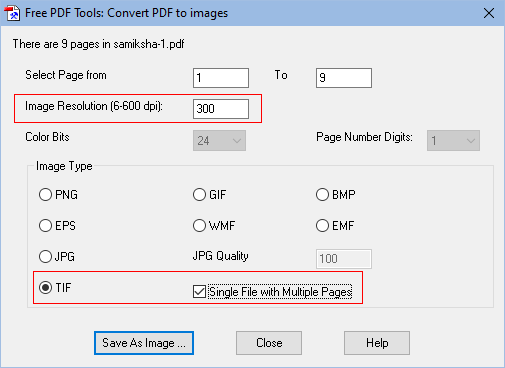
Step 4: Click 'Save As Image' and convert the PDF to an image file - 'samiksha-1.tif'
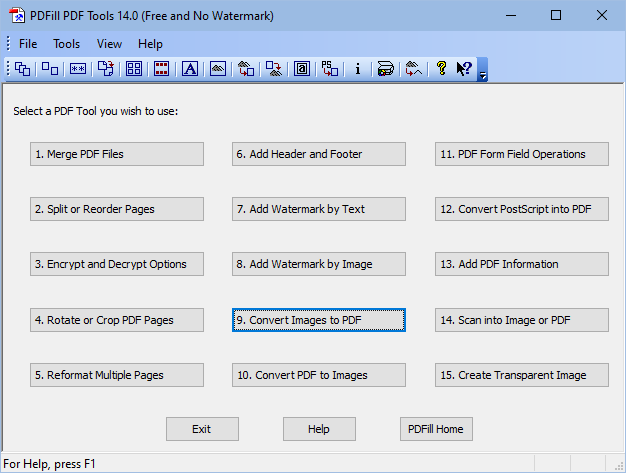
Step 5: Now, click on 'Convert Images to PDF' button (in the same 'PDFill PDF Tools' application). Click on 'Add an Image' and add the 'samiksha-1.tif' file for processing. Then, click on 'Save As ...' button to convert 'samiksha-1.tif' to a new PDF file - for e.g., 'samiksha-1-using-tif-generated-from-pdfilltools.pdf'. Please see screenshot below for better understanding.
Step 6: Upload 'samiksha-1-using-tif-generated-from-pdfilltools.pdf' to your Google Drive. If you have a gmail account, then you will have a 'Google Drive' associated with it (to store your various documents online). If you do not have a gmail account, then you need to create one.
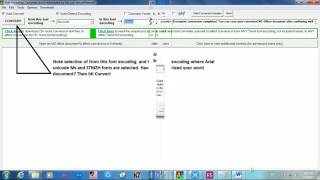
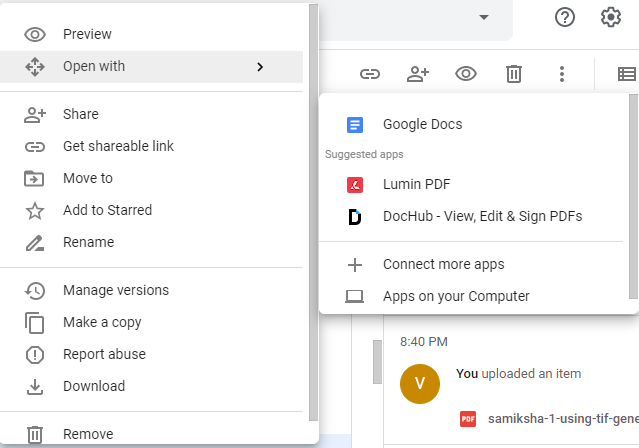
Step 7: Right click on the uploaded pdf file and then click on 'Open with' and then click on 'Google Docs'. See screenshot below for better understanding.
Step 8: Your PDF file will get converted to an editable document and get displayed in docs.google.com. You can copy/paste the text from therein to MS Word, Notepad, etc. But it is better to just download the document into your system as an MS Word document. To do the same, click on "File->Download->Microsoft Word (.docx)". And, your document will get downloaded as samiksha-1-using-tif-generated-from-pdfilltools.docx
Step 9: Open 'samiksha-1-using-tif-generated-from-pdfilltools.docx' and you can see that the objective set forth at the start having been accomplished. i.e. you have converted the original PDF document into an MS Word document with all the Tamil/Sanskrit words readable clearly. Of course, editable too - using Azhagi+, etc. One thing you will observe is that 100% accuracy will not be there. You will need to make corrections at one or two places. But, overall, around 99% will be accurate. Also, formatting will not be as in the original PDF. You need to reformat.
The main objective is to get the Tamil (Hindi, etc.) text in a PDF file in an editable format so that you can do further processing on it (whatsoever). And, you can achieve the same by following the above steps, at any time.
Important Info and Tips:
If your pdf file has lots of pages, then it is better to convert your pdf to editable document, 10 pages at a time, since according to some users, Google Docs seems to take an indefinitely long time and most often it is not successful if there are lots of pages (e.g. 100 pages). Actually, my experience was different. For lots of pages, what Google Docs did was to return an empty document as ouput. So, I tried incrementally and found out (for a particular pdf) that upto 80 pages, there was no problems. Google Docs gave its usual output in a few seconds. But for more than 80 pages, it was all blank outputs only, displayed after a very few seconds.
Note-2:
If your pdf has information in two or more columns in each page, then you need to first create the images columnwise too for each page. i.e. if there are 2 columns in each page, then you need to create images for each of those 2 columns. For the same, you shall use a freeware like BRISS
Note-3:
If you face any difficulty because of the above restrictions, then there is an alternate solution (all thanks in TONS to Shri. Sundar Rajan sir and Mr Shrinivasan) that I came to know of OCRMYPDF. I can always suggest it to tech-savvy persons and those who are not tech-savvy yet willing to explore. This solution is lot easier and straightforward (no need to create images at all) but still it may be longwinding for you since in general it is LINUX-based (using a freeware ocrmypdf) and, in my humble opinion, you have to be technically savvy to a very good extent, to effect that solution. If interested, you can post in https://www.facebook.com/groups/Azhagi for that solution. Alternately, you can do this in Windows too but you need to have Windows10. You need to effect the instructions here. I have tried this out myself. It is easier and produces an ouptut in both PDF and text format but has its own drawbacks - the pdf ouput is perfect but still it is in PDF format itself AND the text output is far less accurate than Google Docs' output. For me, personally, this is a deal breaker. For some, it may not be. Well, if at all you (the reader of this page) get to come across a better alternative (than Google Docs), for normal users, kindly let me know. Tech-savvy users can always decide which one suits them best - GOOGLEDOCS or OCRMYPDF.
Note-4:
I have not been and I am not getting paid by any entity (whatsoever) to do detailed writeups like above. I am hosting such writeups just for the benefit of the society. That's all to it. I do not earn anything from any source. I am not interested or inclined to earn anything (from any source) in the future too. In this regard, if interested, you can read my recent post in my personal Facebook account, carrying the words of Sri Robert Adams (one of the greatest disciples of Sri Ramana Maharishi), which starts as "Lord KRISHNA and Sri Arjuna". And, in the same vein, I am reminded of Lord Buddha's quote too: "Money is the worst discovery of human life. But, it is the most trusted material to test human nature." (Source: http://www.quotss.com/quote/Money-is-the-worst-discovery-of-human-life-but-it-is-the-most-trusted)
At this juncture (also), I humbly thank my better-half, who has been a Himalayan pillar of support (medical support, financial support, moral support, ..., ..., and most importantly spiritual support) through years together. She is God-like. At the worldly level, as such, she is the author of Azhagi. Because, if not for her, it would have been almost impossible for me to continue my journey with Azhagi, from 1999 to this far.
Note-5:
If you have any doubts in the above steps, particularly basic/fundamental doubts (for e.g. 'What is Google Drive and how to use it?'), kindly ask any of your near/dear/friends/relatives/contacts/etc. who are in the field of computing. (I mean, in the IT (information technology) field, 'computer software' development field). I am very sure, in this modern age of expansive use of computers/mobiles/etc., you can definitely find one (amongst your near/dear/friends/relatives/contacts/etc.) who can help you out in this regard. In the past (until perhaps 2 or 3 years ago too), I used to answer basic doubts too (even over phone) but in recent years, due to various reasons (incl. my decades-long fickle health), it has become increasingly difficult to answer doubts (particularly, basic doubts) on a writeup, which is already in great detail. So, kindly bear with me.
Note-6:
Along with very many other queries (you can see a few of them here, the above query (on converting PDF/Images to editable text) also emerges from users every now and then. So, kindly spread the news of my above writeup, if at all possible for you. You can spread it in whatever form you feel like. I mean, if you do not want to mention about azhagi.com (for whatever reasons) but just want to convey the method put up by me above alone, so be it. It does not matter to me in what way you choose to spread it but just spread the news, if at all possible for you. Somewhere somebody will surely get benefited. Even if one person gets benefited, that itself is an enormous help to the society. Eveything is a chain reaction. We never know which help to whom benefits the society in what big way. Yes, we never know. In this regard, kindly see this message from Sri Vikram Mahesh whom I never knew prior to receiving this message from him.

Date of creation (of this web page):
6-October-2019 [Sunday]
Following is the PDF file, 'Samiksha-1.pdf', received from an user more than 2 weeks ago (in Sep 2019). Apart from English, it contains Tamil and Sanskrit characters too. The request from user was to help him convert the text in the PDF file to a suitable form such that he can extract that text and paste it in MS Word and read/edit the Tamil and Sanskrit text. If you observe carefully, the text is selectable from the PDF file but if you copy/paste the text in MS Word, Notepad, etc., the Tamil or Sanskrit words in the PDF file will not be decipherable. Hence, the request from the user. This kind of query comes up again and again from users, since they are not aware of what to do and how to do it. So, the objective is to convert this PDF file to such a format so that the Tamil/Sanskrit words are readable clearly and also editable. The steps for the same are listed below, if you scroll down further.
Step 1: Download and install the supremely useful 'PDFill PDF Tools' (100% FREE) from http://www.pdfill.com/pdf_tools_free.html. Note: You can use any other application to which you are accustomed to, too. I prefer 'PDFill tools'. That's all to it.
Step 2: After successful installation, start the 'PDFill PDF Tools' application and click on 'Convert PDF to Images'. Open 'Samiksha-1.pdf'.
Step 3: Then, make note of the highlighted areas in the screenshot below and keep/select your settings accordingly (i.e. 300 DPI and TIF image format). The image format can be JPG also but I prefer TIF format (Single File with Multiple Pages).
Step 4: Click 'Save As Image' and convert the PDF to an image file - 'samiksha-1.tif'
Step 5: Now, click on 'Convert Images to PDF' button (in the same 'PDFill PDF Tools' application). Click on 'Add an Image' and add the 'samiksha-1.tif' file for processing. Then, click on 'Save As ...' button to convert 'samiksha-1.tif' to a new PDF file - for e.g., 'samiksha-1-using-tif-generated-from-pdfilltools.pdf'. Please see screenshot below for better understanding.
Step 6: Upload 'samiksha-1-using-tif-generated-from-pdfilltools.pdf' to your Google Drive. If you have a gmail account, then you will have a 'Google Drive' associated with it (to store your various documents online). If you do not have a gmail account, then you need to create one.
Step 7: Right click on the uploaded pdf file and then click on 'Open with' and then click on 'Google Docs'. See screenshot below for better understanding.
Step 8: Your PDF file will get converted to an editable document and get displayed in docs.google.com. You can copy/paste the text from therein to MS Word, Notepad, etc. But it is better to just download the document into your system as an MS Word document. To do the same, click on "File->Download->Microsoft Word (.docx)". And, your document will get downloaded as samiksha-1-using-tif-generated-from-pdfilltools.docx
Step 9: Open 'samiksha-1-using-tif-generated-from-pdfilltools.docx' and you can see that the objective set forth at the start having been accomplished. i.e. you have converted the original PDF document into an MS Word document with all the Tamil/Sanskrit words readable clearly. Of course, editable too - using Azhagi+, etc. One thing you will observe is that 100% accuracy will not be there. You will need to make corrections at one or two places. But, overall, around 99% will be accurate. Also, formatting will not be as in the original PDF. You need to reformat.
The main objective is to get the Tamil (Hindi, etc.) text in a PDF file in an editable format so that you can do further processing on it (whatsoever). And, you can achieve the same by following the above steps, at any time.
Important Info and Tips:
- You can achieve the above via your mobile too using Google Translate or Google Lens apps. But, better to use the aforesaid mobile apps only if you have one or two pages/images to convert. For larger no. of pages/images, the above 9-Steps method is the best and less time-consuming one.
- Using Google's apps, you can do OCR for even sheets of text written by you in your own handwriting, even those from the long past. You can instantly do OCR of texts in images, books, handwritten notebooks, newspapers, magazines, web pages, etc. All you have to do is to scan them using your mobile's camera!!! That's all to it. And they will instantly get converted to editable text.
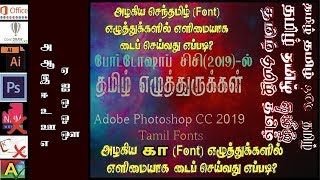
- The final converted text (from Google Docs) will be in Unicode. So, if you wish to have it in the original Non-Unicode font used in the PDF OR any other Non-Unicode font, that can be easily done (instantly, even for large amounts of text) using Azhagi+'s inbuilt Tamil Fonts Converter. It can convert from Unicode to Shreelipi or STMZH or Vanavil or any other non-unicode font you wish to, instantly. It can convert both plain texts and also formatted MS-Word documents.
- If you upload the original PDF file (samiksha-1.pdf) itself and try the above steps, then the final MS Word document you obtain will be like this and you can observe that our objective has not been met.
- Following is the 'samiksha-1-using-tif-generated-from-pdfilltools.pdf' obtained in 'Step 6' above. You cannot select the text in this PDF since all the text is in image format inside the PDF. And this is exactly the kind of PDF file 'Google Docs' is able to convert successfully to a document with editable text.
- In the 'Related Links', at the very start of this page, I have given reference to two posts from Azhagi Facebook Group. Please read them "fully". i.e. Expand each thread fully, including all the comments contained in it (by clicking 'See more', wherever it appears). Because, they contain useful tips, video demos, etc. from users. Anyway, for your convenience, some extracts from them hereunder:
- If you are intending to scan some books and then later on convert the scanned images to editable text, then scan your book page by page only. Do not scan both sides of the pages. If that is not possible (or you already have scanned images of the book which consist of both pages in one image), then cut the images at the center and separate them into two separate images, each carrying a single page only.
- If you are intending to convert old Tamil (Hindi, etc.) books, then:
- As far as possible, ensure that your scanned images are finally in black&white or gray-scale. If letters are in colors (esp. light colors), 'Google Docs' is unable to OCR them (i.e. convert to editable text) properly.
- When scanning, set the DPI level to minimum 200. 300 is always better.
- If you save your scanned images in TIF format, sometimes OCR does not act properly. If the images are in JPG format, the OCR always acts well.
- By adopting the above tips, you can OCR (i.e. convert to editable text) your old/new Tamil (Hindi, etc.) books (magazines, newpaper cuttings, etc.) in a very efficient manner.
- A Tamil translation of the above 4 tips is as follows:
- முடிந்தவரை Scan செய்யப்படும் பக்கத்தை கருப்பு வெள்ளை அல்லது சாம்பல் நிறத்திற்கு மாற்றிக் கொள்ளவும். வண்ணத்தில் சில நிறங்களை, குறிப்பாக மங்கலான வண்ணங்களை, 'Google Docs'-ஆல் சரியாக கன்வெர்ட் செய்ய முடிவதில்லை.
- Scan செய்யும்போது DPI settings 200 DPI முதல் 300 DPI வரைக்கும் இருக்குமாறு பார்த்துக் கொள்ளவும்.
- Scan செய்ததை TIF Format-ல் சேமித்தால், சில சமயங்களில் OCR செயல் படுவதில்லை. JPG Format-ல் சேமித்தால் எப்பொழுதும் சரியாகச் செயல்படுகிறது.
- மேற்கூறியவாறு செய்வதின் மூலம் பழைய பக்கங்களை மிகச் சிறந்த முறையில் தமிழ் (ஹிந்தி, etc.) மொழிகளுக்கு OCR செய்ய முடியும்.
- If you wish to use Google lens to instantly convert your handwritten old letters/poems/stories/etc., pages of old/new magazines/books/newpapars/etc., then watch this video demo in Azhagi's Facebook Group
If your pdf file has lots of pages, then it is better to convert your pdf to editable document, 10 pages at a time, since according to some users, Google Docs seems to take an indefinitely long time and most often it is not successful if there are lots of pages (e.g. 100 pages). Actually, my experience was different. For lots of pages, what Google Docs did was to return an empty document as ouput. So, I tried incrementally and found out (for a particular pdf) that upto 80 pages, there was no problems. Google Docs gave its usual output in a few seconds. But for more than 80 pages, it was all blank outputs only, displayed after a very few seconds.
Note-2:
If your pdf has information in two or more columns in each page, then you need to first create the images columnwise too for each page. i.e. if there are 2 columns in each page, then you need to create images for each of those 2 columns. For the same, you shall use a freeware like BRISS
Note-3:
If you face any difficulty because of the above restrictions, then there is an alternate solution (all thanks in TONS to Shri. Sundar Rajan sir and Mr Shrinivasan) that I came to know of OCRMYPDF. I can always suggest it to tech-savvy persons and those who are not tech-savvy yet willing to explore. This solution is lot easier and straightforward (no need to create images at all) but still it may be longwinding for you since in general it is LINUX-based (using a freeware ocrmypdf) and, in my humble opinion, you have to be technically savvy to a very good extent, to effect that solution. If interested, you can post in https://www.facebook.com/groups/Azhagi for that solution. Alternately, you can do this in Windows too but you need to have Windows10. You need to effect the instructions here. I have tried this out myself. It is easier and produces an ouptut in both PDF and text format but has its own drawbacks - the pdf ouput is perfect but still it is in PDF format itself AND the text output is far less accurate than Google Docs' output. For me, personally, this is a deal breaker. For some, it may not be. Well, if at all you (the reader of this page) get to come across a better alternative (than Google Docs), for normal users, kindly let me know. Tech-savvy users can always decide which one suits them best - GOOGLEDOCS or OCRMYPDF.
Note-4:
I have not been and I am not getting paid by any entity (whatsoever) to do detailed writeups like above. I am hosting such writeups just for the benefit of the society. That's all to it. I do not earn anything from any source. I am not interested or inclined to earn anything (from any source) in the future too. In this regard, if interested, you can read my recent post in my personal Facebook account, carrying the words of Sri Robert Adams (one of the greatest disciples of Sri Ramana Maharishi), which starts as "Lord KRISHNA and Sri Arjuna". And, in the same vein, I am reminded of Lord Buddha's quote too: "Money is the worst discovery of human life. But, it is the most trusted material to test human nature." (Source: http://www.quotss.com/quote/Money-is-the-worst-discovery-of-human-life-but-it-is-the-most-trusted)
At this juncture (also), I humbly thank my better-half, who has been a Himalayan pillar of support (medical support, financial support, moral support, ..., ..., and most importantly spiritual support) through years together. She is God-like. At the worldly level, as such, she is the author of Azhagi. Because, if not for her, it would have been almost impossible for me to continue my journey with Azhagi, from 1999 to this far.
Note-5:
If you have any doubts in the above steps, particularly basic/fundamental doubts (for e.g. 'What is Google Drive and how to use it?'), kindly ask any of your near/dear/friends/relatives/contacts/etc. who are in the field of computing. (I mean, in the IT (information technology) field, 'computer software' development field). I am very sure, in this modern age of expansive use of computers/mobiles/etc., you can definitely find one (amongst your near/dear/friends/relatives/contacts/etc.) who can help you out in this regard. In the past (until perhaps 2 or 3 years ago too), I used to answer basic doubts too (even over phone) but in recent years, due to various reasons (incl. my decades-long fickle health), it has become increasingly difficult to answer doubts (particularly, basic doubts) on a writeup, which is already in great detail. So, kindly bear with me.
Note-6:
Along with very many other queries (you can see a few of them here, the above query (on converting PDF/Images to editable text) also emerges from users every now and then. So, kindly spread the news of my above writeup, if at all possible for you. You can spread it in whatever form you feel like. I mean, if you do not want to mention about azhagi.com (for whatever reasons) but just want to convey the method put up by me above alone, so be it. It does not matter to me in what way you choose to spread it but just spread the news, if at all possible for you. Somewhere somebody will surely get benefited. Even if one person gets benefited, that itself is an enormous help to the society. Eveything is a chain reaction. We never know which help to whom benefits the society in what big way. Yes, we never know. In this regard, kindly see this message from Sri Vikram Mahesh whom I never knew prior to receiving this message from him.
Date of creation (of this web page):
6-October-2019 [Sunday]